機械学習を用いた
ソーシャル時系列情報の解析と利用
研究概要
情報爆発社会といわれる現代では、情報発信のハードルが非常に低くなり、今までのどの時代とも比べものにならないほど大量な情報が毎日発信されています。特に、TwitterやFacebookに代表されるソーシャルメディアから、人々の日々の思考や行動、そして他人とやり取りに関する情報の本体に、著者、時間と場所などのメタ情報が付加されて大量に発信されます。これらの情報は社会的な情報基盤となりうる重要な一次的リソースであります。これら一次的リソースを収集して解析することで、情報の生成、変遷や拡散など二次情報を抽出することができれば、世論調査、政策決定、マーケティングなどに大きな変革をもたらすでしょう。我々の研究では、トピックモデルや重回帰分析に基づき、コンピュータ処理によって大量の一次情報から自動的分類を行い、個別情報間の関連性や時間と場所に伴った情報の変化など二次情報を抽出します。その上で、セキュリティリスク情報の検出、政党支持率の予測、会社や商品の評判解析など具体的な課題に取り組んでいます。
トピックモデルを用いたテキスト文書のマルチラベル自動付与に関する研究
トピックモデルでは、一つの文書は複数のトピックによって構成されるとしています。一方では、与えられた文書にその内容の特徴を表す複数のラベルを自動的に付与することが必要とされています。本研究では、トピックモデルと最小平均自乗推定との結合により、マルチラベル自動分類の手法を提案しました。まずはトピックモデルのLDA法によって各文書のトピック分布を抽出しました。そして、これら文書のトピック分布を、対応する文書の複数ラベルとセットにして、最小平均自乗推定に基づきマルチラベル分類器の構築を行い、大量のテキスト文書に自動的にマルチラベルを付与することが実現できました。
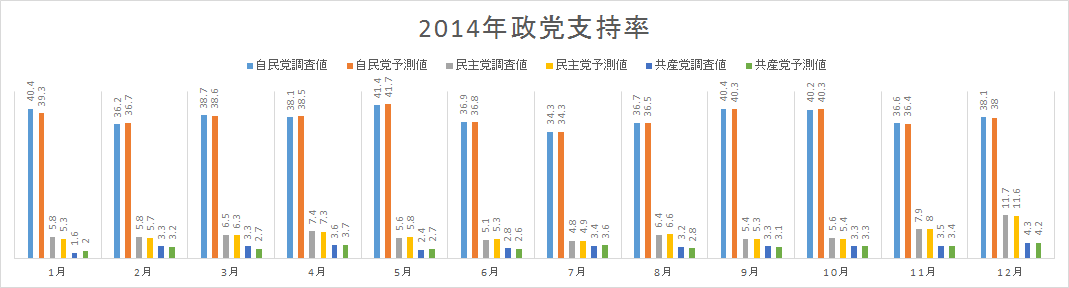
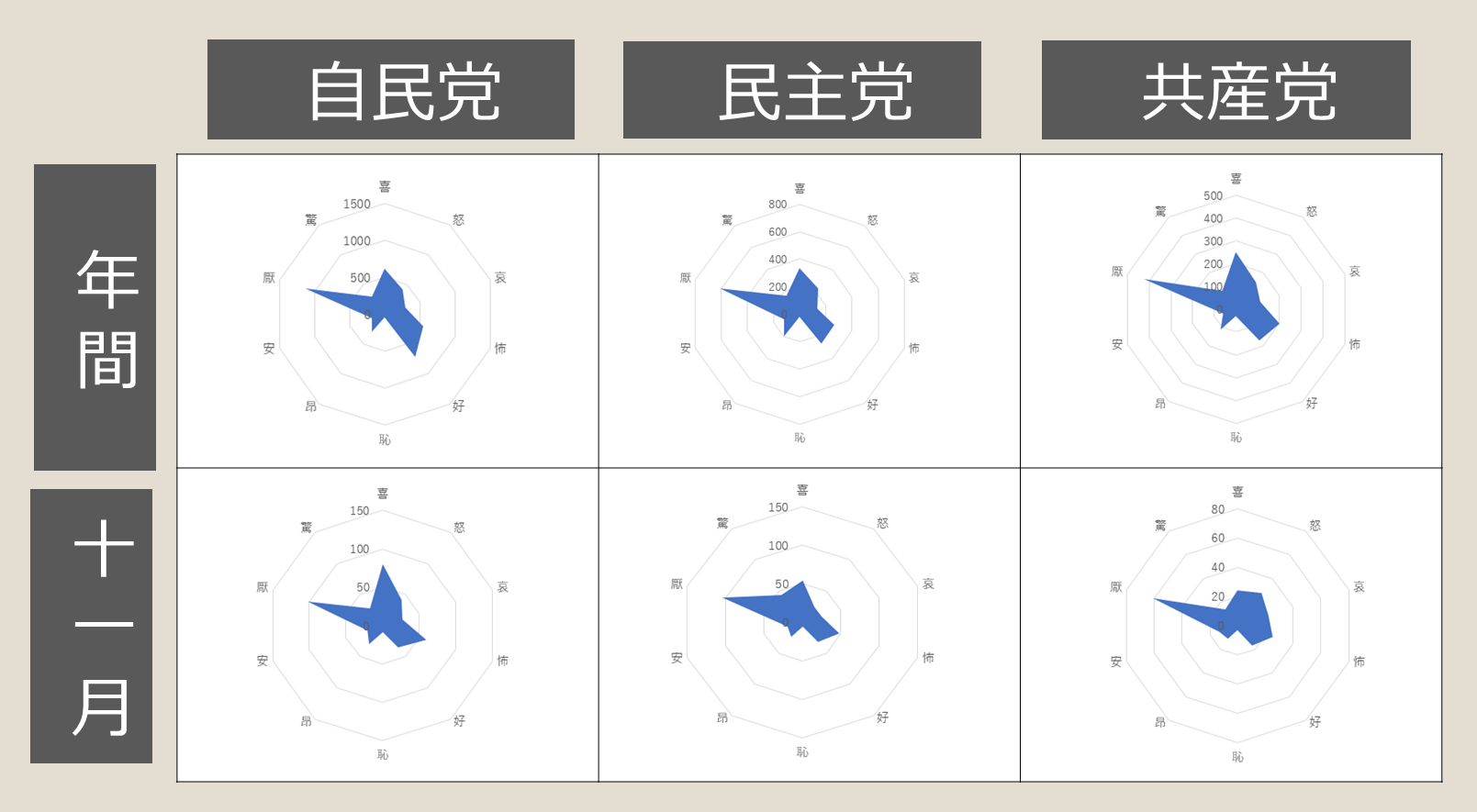
Twitterからの多軸的感情情報に基づく政党支持率の予測に関する研究
本研究では、Twitter からの多軸的に感情を数値化し、政党支持率を予測できるシステムを構築しました。まずは言葉の感情表現を喜・怒・哀・怖・恥・好・厭・昂・安・驚の10 軸に分けて、各々の感情軸にその感情を表す単語が付与し感情辞書を作成しました。そして、この感情辞書を参考にツイートから感情情報を数値化し、政党に関するツイートの感情ベクトルを求めました。その上で政党の感情ベクトルを説明変数、月ごとの政党支持率を目的変数とする重回帰分析を行なうことで、各感情軸に関する回帰係数を求め政党支持率の予測を試み、比較的高い精度に達成することができました。